CSS Selectors for Tests
When we test web pages, we usually have to interact with CSS selectors. That is true of libraries like Wallay and Hound, which interact with web drivers, but it’s also true of Phoenix LiveView.
During my Testing LiveView course, someone asked how I choose CSS selectors for tests. To my surprise, I found that I had some opinions.
Resilient CSS Selectors
When choosing CSS selectors to target elements in our tests, I like to keep in mind that developers are not the only people in our team who use HTML elements and their attributes.
That means there are many reasons why our markup might change, and most changes are probably unrelated to our tests. So, one of my primary goals is to find CSS selectors that can withstand unrelated changes to the HTML markup.
| Types of changes | Should break our tests? |
|---|---|
| Changes in styling (e.g. ".active" -> ".selected") | NO |
| Changes in the structure of the page (e.g. "table" -> "grid" or "flex") | NO |
| Changes in the position of an element within the page (unless, of course, the relative position of elements is important). | NO |
| The presence or absence of the element from the page | YES! 💥 |
I want to use CSS selectors that identify whether or not something is on the page but which are decoupled from styling, the exact HTML element used, and the structure on the page.
Thus, my preferred approach can be summarized with three rules:
- Target specific elements with IDs (since they’re unique on a page),
- Use data attributes (preferably ones that have semantic meaning) to target an element that can be repeated on the page, and
- Combine the two above with descendant combinators to target a generic element nested inside a specific one.
Let’s look at examples.
Using IDs for unique elements
Consider a twitter-clone app. Suppose we want to find out if a post we’ve created is present in the Timeline.
We can target that element based on its ID because the post should be unique.
#post-53 {
border: 0.5rem solid red;
}
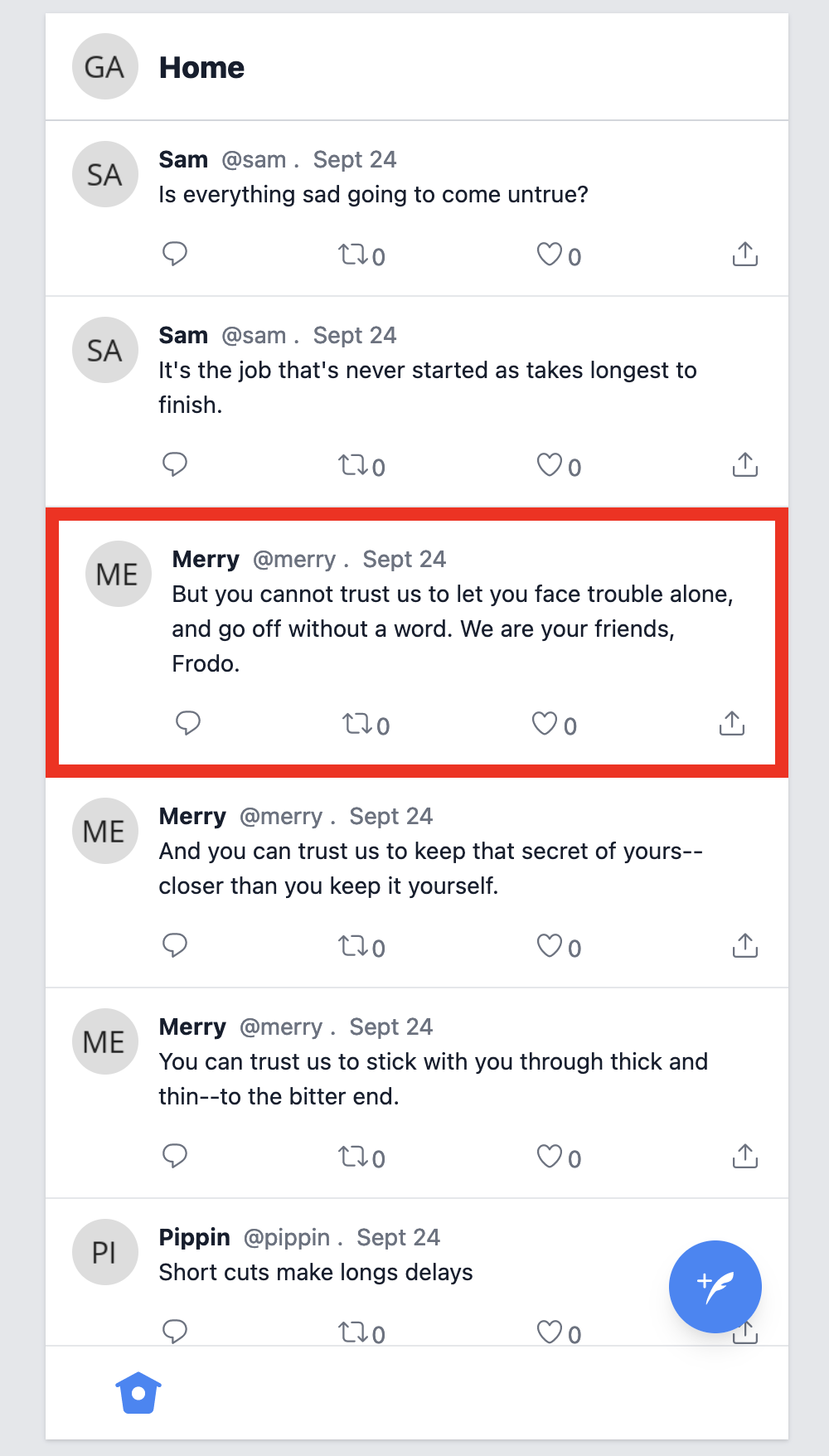
In LiveView, that might look something like this:
post = create(:post)
{:ok, view, _} = live(conn, "/")
assert has_element?(view, "#post-#{post.id}")
The CSS selector is great because it’s specific, and it has little reason for changing since it represents a post uniquely. Colleagues might see it and use it. But if someone removes it, the whole post is likely being removed, and thus our test should fail.
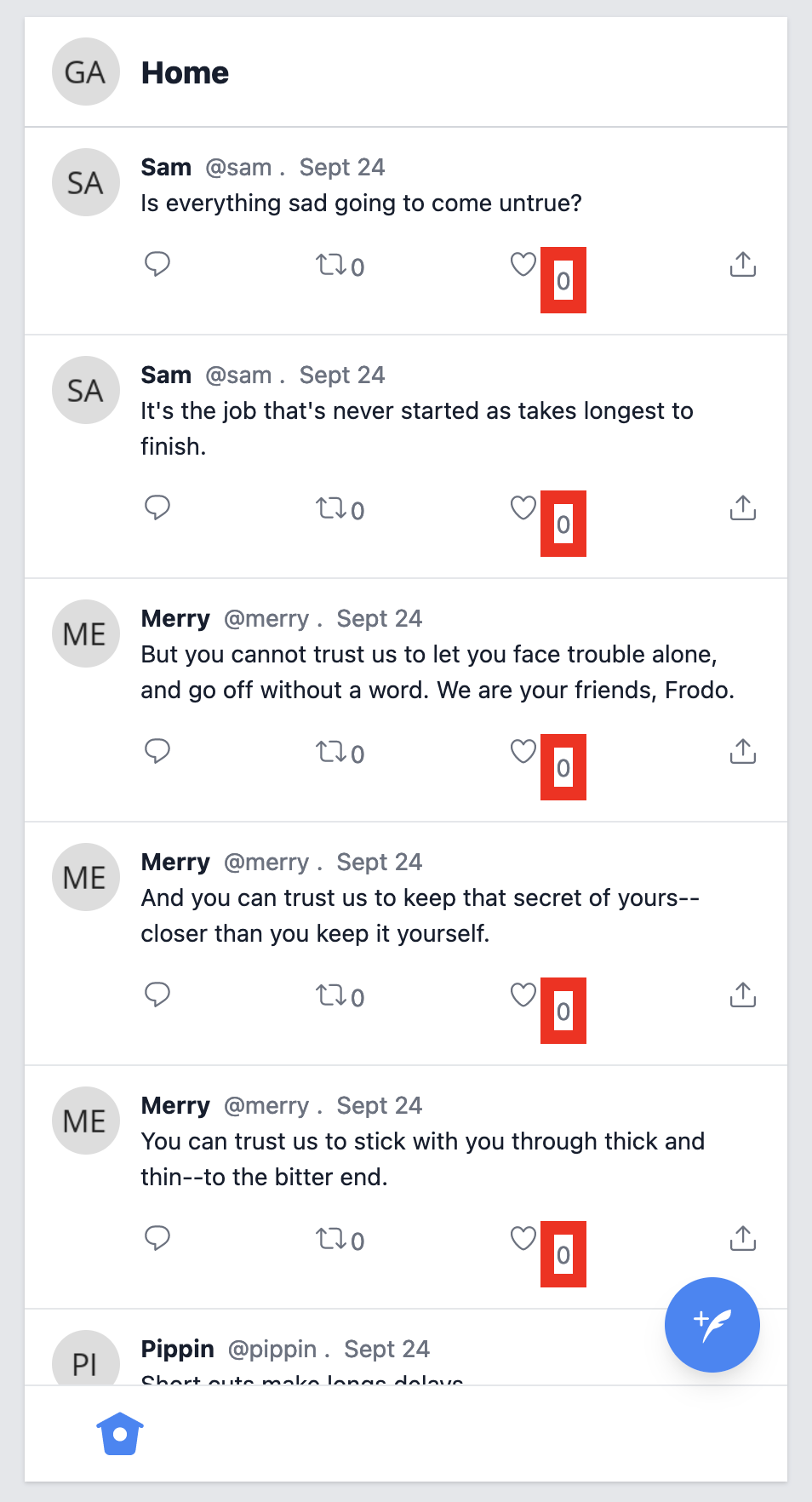
Using data roles for repeated elements
Now let’s suppose we want to target every “like count” that exists on the page. At this point, most people would rely on a CSS class. I prefer data attributes — and I tend to use data roles with some semantic meaning — because CSS classes are very likely to change for styling and can thus make our tests very brittle.
So, in practice, I would go for something like this:
[data-role='like-count'] {
border: 0.5rem solid red;
}
Combining IDs and data roles with descendant combinators
What about more complicated scenarios? We can combine the two previous rules with a descendant combinator and hit 90% of our use cases.
Let’s consider the scenario where we want to test the number of likes for a specific post. The like count is not a unique element, so it may not have an ID, but it is nested inside a post, which is unique.
So, we can target the like count by combining the post ID with the “like-count” data role:
#post-53 [data-role='like-count'] {
border: 0.5rem solid red;
}
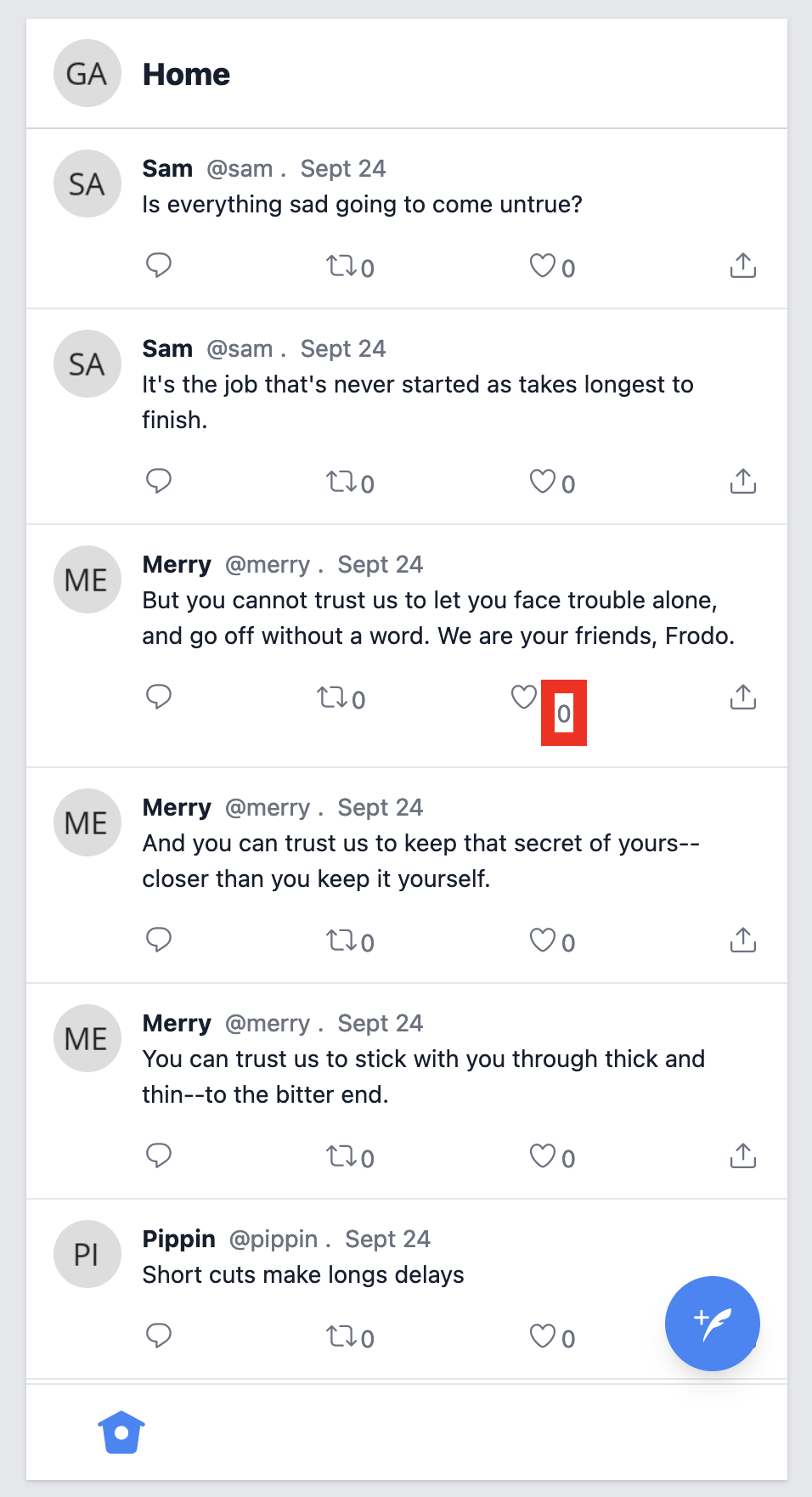
In LiveView, we might assert the number of likes for a given post like this:
post = create(:post, like_count: 23)
{:ok, view, _html} = live(conn, "/")
assert has_element?(view, "#post-#{post.id} [data-role='like-count']", "23")
Now, we can target any element on the page based on its unique and repeated portions!
Resources
If you’re new to CSS selectors or would like to learn more about them, I recommend MDN’s guide on CSS selectors and W3C’s selectors guide.